AI文章摘要
问题在于如何来保留原来的图片风格信息而避免使得原来图片的layout和内容影响现在的内容,所以就有多种方法,比如用现在的来引导原来的图片生成,ipadaptar,另外就是加入额外的信息,比如文本信息,或者通过别的方法加入,如adapter或者是改变某一些层
IP-Adapter
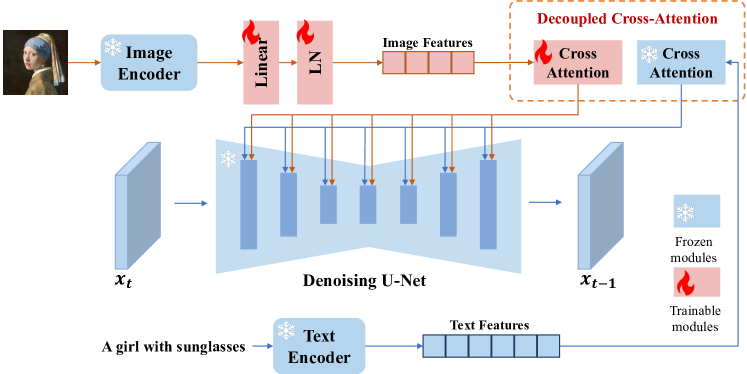
Solution - Separate Cross-Attention Layers: Instead of concatenating the features, a decoupled cross-attention is proposed where separate cross-attention layers are used for text and image features. This means:
For text features: Use the original query from the UNet model (𝐐 = 𝐙𝐖𝑞) with the corresponding key and value matrices for text (𝐾 = 𝒄𝑡𝐖𝑘, 𝐕 = 𝒄𝑡𝐖𝑣).
For image features: Introduce a new set of key and value matrices (𝐾′ = 𝒄𝑖𝐖𝑘′, 𝐕′ = 𝒄𝑖𝐖𝑣′) for the image features, but the query remains the same (𝐐 = 𝐙𝐖𝑞).
Combining Outputs: The outputs of both cross-attention mechanisms (for text and image) are then summed up to produce the final output of the decoupled cross-attention.
因此要再训练
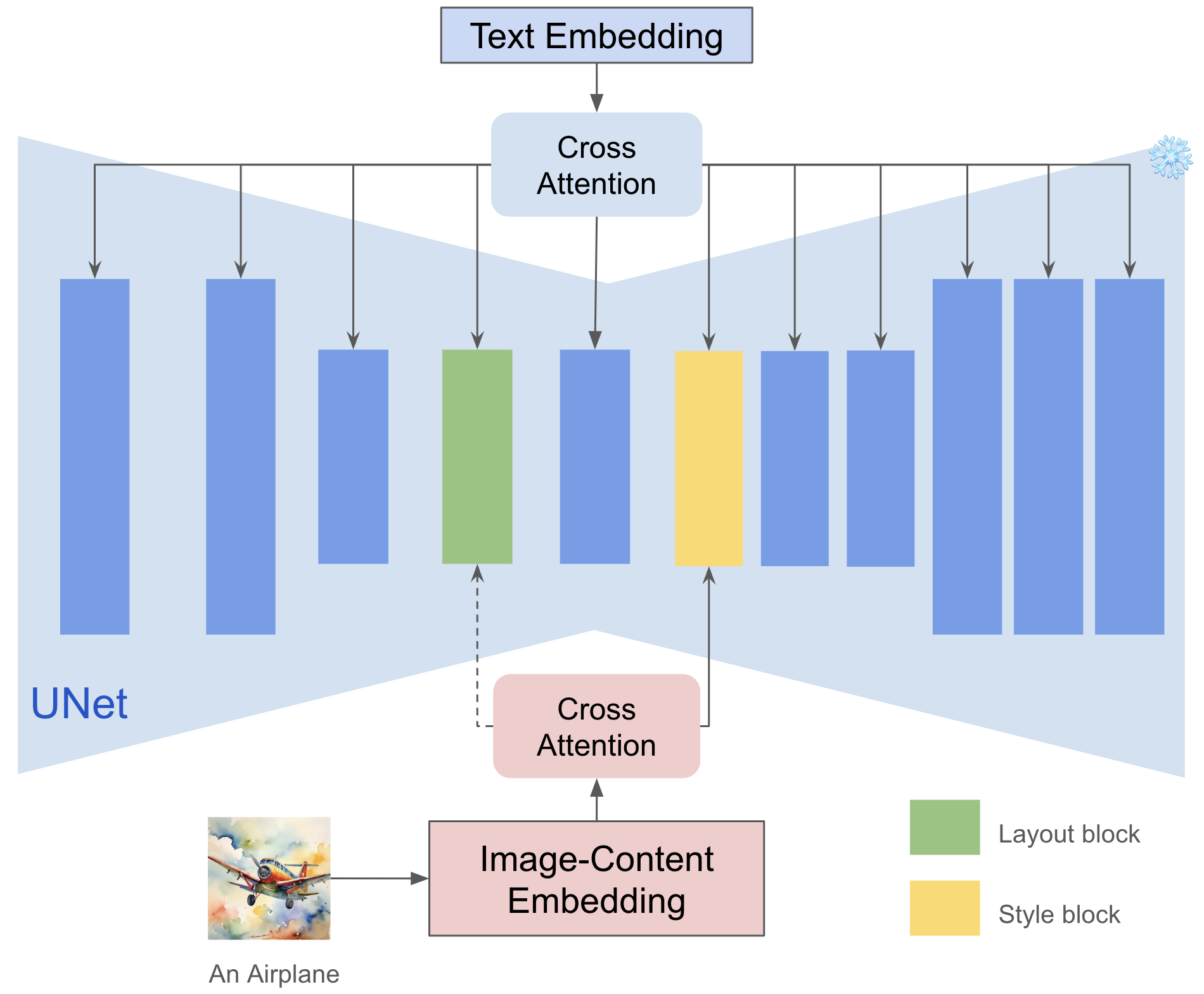
INSTANTSYLE-PLUS
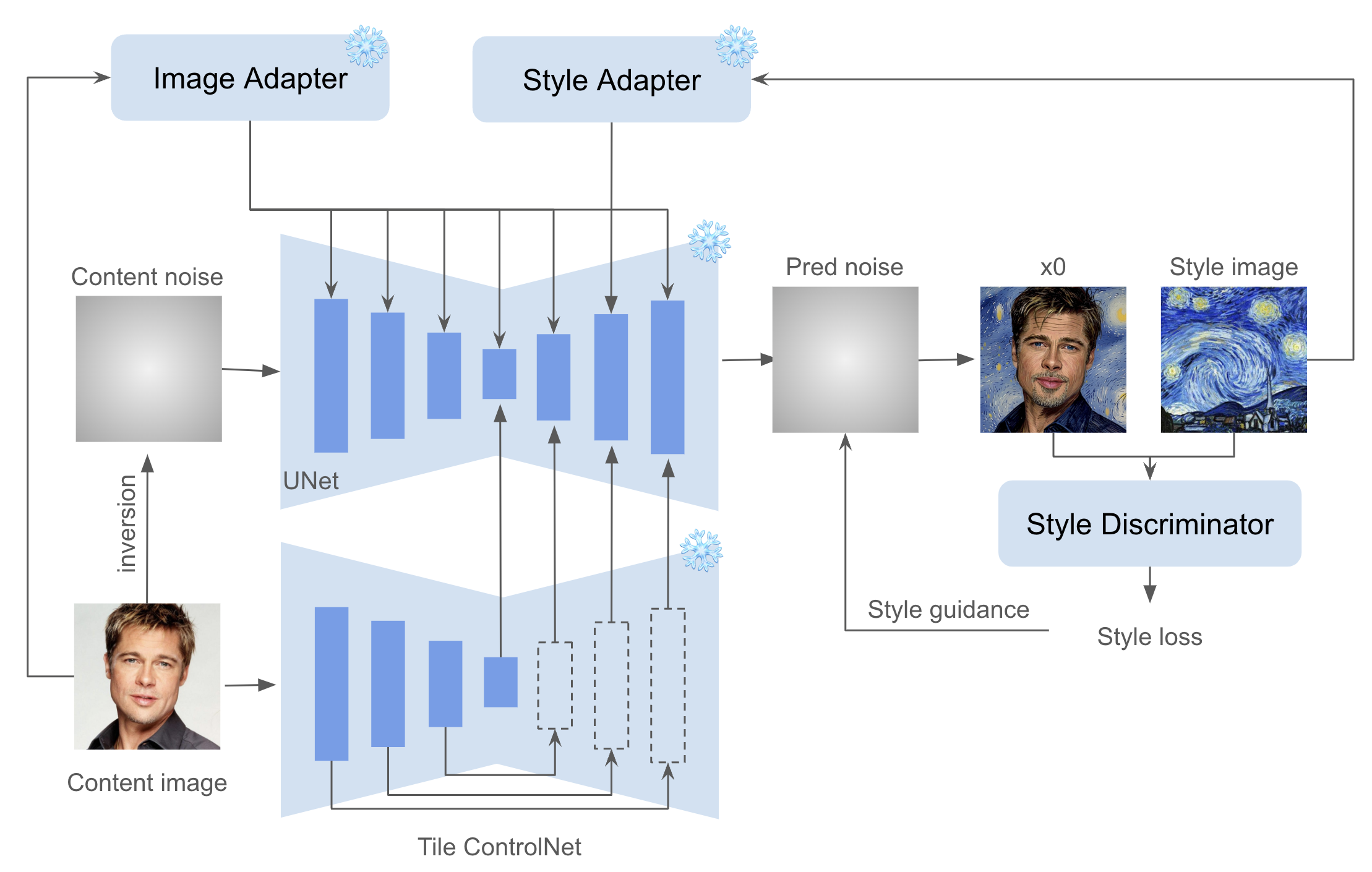
https://github.com/instantX-research/InstantStyle-Plus
For stylistic infusion, we adhere to InstantStyle’s approach by injecting style features exclusively into style-specific blocks. To preserve content, we initialize with inverted content noise and employ a pre-trained Tile ControlNet to maintain spatial composition. For semantic integrity, an image adapter is integrated for the content image. To harmonize content and style, we introduce a style discriminator, utilizing style loss to refine the predicted noise throughout the denoising process. Our approach is optimization-free.
DREAMEBOOTH
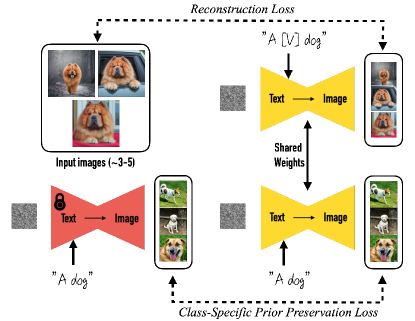
Given ∼3−5 images of a subject we fine-tune a text-to-image diffusion model with the input images paired with a text prompt containing a unique identifier and the name of the class the subject belongs to (e.g., “A [V] dog”), in parallel, we apply a class-specific prior preservation loss, which leverages the semantic prior that the model has on the class and encourages it to generate diverse instances belong to the subject’s class using the class name in a text prompt (e.g., “A dog”).
StyleAdapter
1) the prompt usually loses controllability over the generated content, and 2) the generated image inherits both the semantic and style features of the style reference images, compromising its content fidelity.
Our contributions can be summarized as follows: (2). We introduce a two-path cross-attention module (TPCA) to process the style and prompt features separately, allowing us to balance the impact of these two modalities on the generated images and enhance the controllability of the prompt during the generation process. (3). We propose three strategies to decouple the semantic and style information in the style reference images, improving content fidelity during generation.
Combining the features of the prompt and style reference before injecting them into the generated image results in a loss of controllability of the prompt over the generated content.
研究探讨了缓解风格与语义耦合问题的策略,重点在于保留风格信息并去除语义信息。通过实验验证以下三种方法:
分块打乱参考图像:去除人脸,但风格信息有所减弱。
移除类别嵌入:有效减少语义干扰,生成图像风格损失较小。
使用多风格参考图像:通过多样风格参考增强风格化效果,同时去除语义信息干扰。
最终方法实现了生成风格接近参考图像但语义干扰较少的结果。
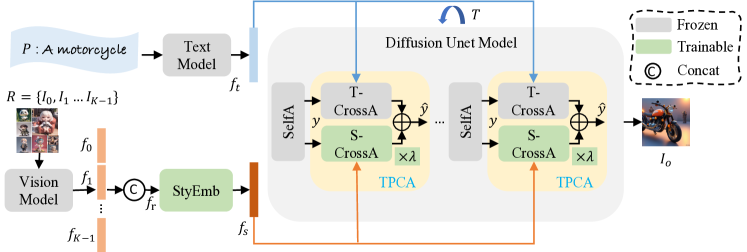
INSTANTSTYLE
图片去除语义信息,分别注入两个层
pre
These innovative methods can be broadly categorized into two distinct groups: 1) Adapter-free[7, 9]: This category of methods leverages the power of self-attention within the diffusion process. By utilizing a shared attention operation, these techniques extract essential features such as keys and values directly from a given reference style image. This allows for a more streamlined and focused approach to image generation, as it draws directly from the stylistic elements present in the reference. 2) Adapter-based[26]: In contrast, adapter-based methods incorporate a lightweight model designed to extract detailed image representations from the reference style image. These representations are then skillfully integrated into the diffusion process via cross-attention mechanisms. This integration serves to guide the generation process, ensuring that the resulting images are aligned with the desired stylistic nuances of the reference.
2.2Stylized Image Generation
Stylized image generation, also often called style transfer, its goal is to transfer the style of a reference image to the target content image. Previous customization works[8, 5, 19] usually fine-tine the diffusion model on a set of images with the same style, which is time-costing and cannot well generalize to real world domain where a subset with shared style is hard to collect. Recently, there has been a surge in interest in developing tuning-free approaches[20, 26, 25, 7, 9, 15, 3] for stylized image generation. These works use lightweight adapters to extract image features and inject them into the diffusion process through self-attention or cross-attention. IP-Adapter[26] and Style-Adapter[25] share the same idea where a decoupled cross-attention mechanism is introduced to separate cross-attention layers for text features and image features. However, they suffer from content leakage more or less as suggested in [9]. StyleAlign[7] and Swapping Self-Attention[9] swap the key and value features of self-attention block in an original denoising process with the ones from a reference denoising process. But for real world images, they requires an inversion to turn image back to a latent noise, leading to a loss of fine-grained details such as texture and color, thereby diminishing the style information in the generated images. DEADiff[15] aims to extract disentangled representations of content and style utilizing a paired dataset and Q-Former[11]. However, due to the inherently underdetermined nature of style, the construction of large-scale paired datasets is resource-intensive and limited in the diversity of styles. For style transfer, we support lightweight modules such as IP-Adapter[26] because of its portability and efficiency. The only problem is how to complete the decoupling of content and style in images.
2.3Attention Control in Diffusion Models
As shown in [6], self-attention and cross-attention blocks within diffusion process determine different attributes, such as spatial layout and content of the generated images. Image editing approaches [1, 12, 22] apply attention control to enable structure-preserving image edit. P+[23] demonstrates that different cross-attention layers in the diffusion U-Net express distinct responses to style and semantics, provides greater disentangling and control over image synthesis. Swapping Self-Attention [9] reveals that upblocks in UNet appropriately reflect the style elements, while bottleneck and downblocks cause content leakage. DEADiff[15] introduces a disentangled conditioning mechanism that conditions the coarse layers with lower spatial resolution on semantics, while the fine layers with higher spatial resolution are conditioned on the style. A more recent work, B-LoRA[3] find that jointly learning the LoRA weights of two specific blocks implicitly separates the style and content components of a single image. Our work is mostly inspired by these works, and we aim to identify the most style-relevant layers for disentangling content and style in style transfer.
3.2.3The impact of different blocks is not equal.
In the era of convolutional neural networks, many studies have found that shallow convolutional layers will learn low-level representations, such as shape, color, etc., while high-level layers will focus on semantic information. In diffusion-based models, the same logic exists as found in [3, 23, 15]. Like text conditions, image conditions are generally injected through cross attention layer to guide generation. We found that different attention layers capture style information differently. In our experiments as shown in Figure 7, we found that there are two special layers that play an important role in style preservation. To be more specific, we find up_blocks.0.attentions.1 and down_blocks.2.attentions.1 capture style (color, material, atmosphere) and spatial layout (structure, composition) respectively, the consideration of layout as a stylistic element is subjective and can vary among individuals.
Style Aligned
改进方法:跨图像共享自注意力 该方法的关键创新是通过共享自注意力层来实现不同图像之间的“风格对齐”。这意味着在更新图像特征时,注意力层可以跨多个生成的图像进行通信,从而使它们共享相同的风格。 注意力共享的过程包括:将每个图像的深层特征投影成查询、键和值,然后计算跨所有图像的注意力。这有助于生成的图像在风格上保持一致。
挑战:避免内容泄漏并促进多样性 在所有图像之间共享注意力可能会导致内容泄漏,即一个图像的内容影响到其他图像,从而造成不想要的混合(例如:一只独角兽被画上恐龙的绿色油漆)。 为了解决这个问题,作者提出只在目标图像和一个参考图像之间共享注意力(通常是批次中的第一个图像)。这样可以避免内容泄漏并促进图像集的多样性。
解决方案:自适应归一化(AdaIN) 为了使目标图像和参考图像之间的风格更好地对齐,方法使用了自适应归一化操作(AdaIN)。 AdaIN操作会使用参考图像的查询和键来对目标图像的查询和键进行归一化,从而确保目标图像的特征能够合理地参考参考图像。 AdaIN操作通过调整目标图像的查询/键的均值和标准差来实现风格对齐,从而提高风格一致性。
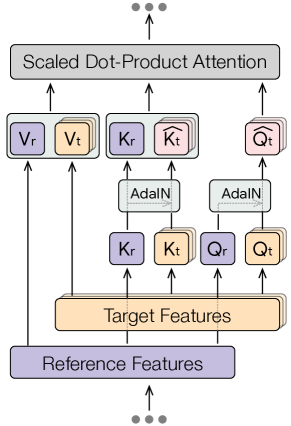
AdaIN的数学表示:
假设目标图像的查询/键(Q/K)是 xxx,参考图像的查询/键是 yyy,则AdaIN操作可以表示为: AdaIN(x,y)=σ(y)⋅(x−μ(x)σ(x))+μ(y)\text{AdaIN}(x, y) = \sigma(y) \cdot \left( \frac{x - \mu(x)}{\sigma(x)} \right) + \mu(y)AdaIN(x,y)=σ(y)⋅(σ(x)x−μ(x))+μ(y)
μ(x)\mu(x)μ(x) 和 σ(x)\sigma(x)σ(x) 分别是目标图像特征 xxx 的均值和标准差。
μ(y)\mu(y)μ(y) 和 σ(y)\sigma(y)σ(y) 分别是参考图像特征 yyy 的均值和标准差。
通过这个操作,目标图像的特征不仅标准化,还根据参考图像的风格(均值和标准差)来进行调整。
为什么使用AdaIN?
风格一致性:AdaIN通过将目标图像的特征调整为参考图像的风格,能够实现目标图像和参考图像之间风格的对齐,从而确保生成的图像在风格上与参考图像一致。
灵活性:这种方式非常灵活,可以将不同的风格应用到不同的图像上,常用于风格迁移任务
评论 (0)